Twitter revela los secretos de su motor de recomendaciones
hace 2 años

Prometido por Elon Musk, Twitter dio a conocer el código fuente de su algoritmo de recomendación a fines de la semana pasada. Disponible en GitHub, se ha diseccionado para comprender el funcionamiento interno.
“Una nueva era de transparencia para Twitter”. El tono está establecido, ha llegado el momento de la responsabilidad. Elon Musk había mencionado repetidamente, antes y después de la adquisición, su deseo de hacer público el código fuente del algoritmo de la red social. Bajo su aire de veleta, finalmente habrá cumplido su palabra este 31 de marzo anunciándolo en Twitter. En GitHub, cualquiera puede encontrar dos repositorios (main repo, ml repo) que contienen el código fuente de su algoritmo de recomendaciones. Fue lanzado bajo la Licencia Pública General GNU Affero v3.0.
Tenga en cuenta que el lanzamiento no incluye código relacionado con la seguridad y privacidad del usuario o la capacidad de proteger su plataforma de los malos actores. En su declaración, Twitter también afirma que "el lanzamiento tampoco incluye el código que impulsa nuestras recomendaciones publicitarias. También hemos tomado medidas adicionales para garantizar que la seguridad y la privacidad del usuario estén protegidas, incluida nuestra decisión de no publicar datos de entrenamiento o pesos de modelos". asociado con el algoritmo de Twitter en este momento".
Una tubería de recomendación de tres pasos
En detalle, la base de las recomendaciones de Twitter es un conjunto de modelos y funciones básicos que extraen información latente de los tuits, los usuarios y los datos de interacción. Estos modelos tienen como objetivo responder preguntas importantes sobre la red de Twitter, como "¿Qué probabilidades hay de que interactúes con otro usuario en el futuro?" o "¿Cuáles son las comunidades en Twitter y cuáles son los Tweets de moda dentro de ellas?" ". Un servicio llamado Home Mixer opera Para Usted. Como dice el equipo de ingeniería “Home Mixer se basa en Product Mixer, nuestro marco Scala personalizado que facilita la creación de flujos de contenido. Este servicio actúa como la columna vertebral del software que conecta diferentes fuentes candidatas, funciones de puntuación, heurísticas y filtros”.
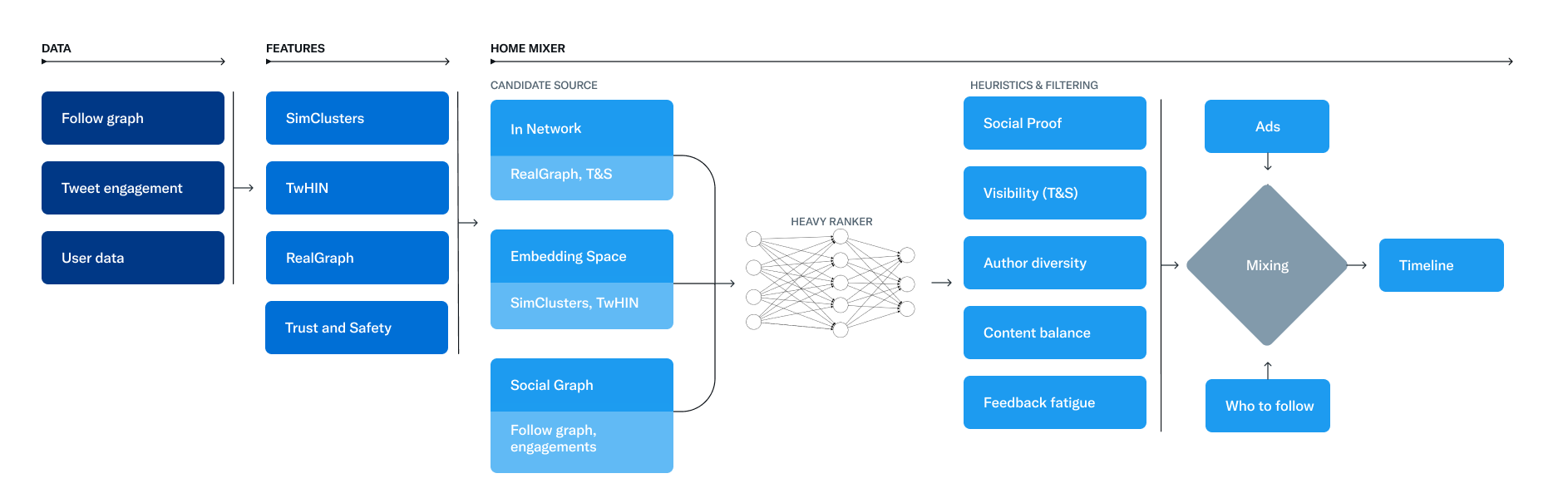
Este diagrama ilustra los principales componentes utilizados para construir una línea de tiempo. (Crédito: Twitter)
La canalización de recomendaciones se compone de tres etapas principales que se basan en estas características. El primero es obtener los mejores Tweets de diferentes fuentes de recomendación en un proceso llamado investigación de candidatos. En segundo lugar, cada tweet se clasifica mediante un modelo de aprendizaje automático. Finalmente, el último paso es aplicar heurísticas y filtros, como filtrar tweets de usuarios bloqueados, contenido NSFW (no seguro para el trabajo) y tweets vistos anteriormente. En cuanto a la elección de las fuentes, Twitter admite hacer una mezcla entre personas seguidas (llamadas In-Network) y personas no seguidas (Out-of-Network). Para ello, extrae los 1500 tuits principales de un grupo de cientos de millones a través de estas fuentes. Hoy en día, la línea de tiempo For You consiste en un promedio de 50 % de Tweets dentro de la red y 50 % de Tweets fuera de la red, aunque esto puede variar de un usuario a otro.
Cuando se clasifican las publicaciones, esto se hace con una red neuronal de 48 millones de parámetros que se capacita continuamente en las interacciones de los tweets para optimizar el compromiso positivo (por ejemplo, me gusta, retweets y respuestas). Este mecanismo de clasificación considera miles de funciones y produce diez etiquetas para otorgar una puntuación a cada tuit, donde cada índice representa la probabilidad de participación. “Clasificamos los tuits a partir de estas puntuaciones”, especifica la firma. Después de este paso, la red social aplica modelos heurísticos y filtros para implementar varias funciones del producto. El objetivo: crear un flujo equilibrado y diversificado. Esto incluye filtrado de visibilidad, diversidad de autores, equilibrio de contenido (entre Tweets dentro y fuera de la red), etc.
Una tubería que se ejecuta 5 mil millones de veces al día
Siguiendo estos tres pasos, Home Mixer tiene un conjunto de tweets listos para ser enviados a cada terminal. Como paso final en el proceso, el sistema mezcla tweets con otro contenido que no es tweet, como anuncios, recomendaciones de seguimiento e indicaciones de incorporación, que se envían a cada dispositivo para su visualización. La tubería se ejecuta aproximadamente 5 mil millones de veces por día y se completa en menos de 1,5 segundos en promedio. La ejecución de una sola canalización requiere 220 segundos de tiempo de CPU, que es casi 150 veces la latencia que el usuario percibe en la aplicación.
Twitter también indica que está abierto a cualquier exposición de problemas en GitHub y está listo para recibir sugerencias sobre cómo mejorar el algoritmo de recomendación. “Estamos trabajando en herramientas para administrar estas sugerencias y sincronizar los cambios con nuestro repositorio interno. Cualquier problema o problema de seguridad debe dirigirse a nuestro programa oficial de recompensas por errores a través de HackerOne. Esperemos que este sea el comienzo de un paso hacia una mayor transparencia de Twitter y que su propietario no decida dar dos pasos atrás en las próximas semanas.
Si quieres conocer otros artículos parecidos a Twitter revela los secretos de su motor de recomendaciones puedes visitar la categoría Otros.
Otras noticias que te pueden interesar