Dado que el mundo de TI comenzó a cubrir el desarrollo de varias aplicaciones de IA, como la generación de imágenes, especialmente con Horda estable - Los depósitos de código en GitHub y los enlaces en Reddit están llenos de modelos AI. Algunos de ellos están de hecho en sitios comerciales, que desarrollan sus propios algoritmos o adaptan otros que se han publicado en código abierto. Un excelente ejemplo de un sitio de audio existente es UberDuck.Aque literalmente ofrece cientos de modelos preprogramados. Es suficiente ingresar el texto en el campo provisto para este propósito para que un Elon Musk, un Bill Gates, un Daffy Duck o incluso un Siri lea las líneas preprogramadas.
Para entrenar una IA para reproducir el discurso, debe descargar muestras de voz claras. AI aprende cómo el altavoz combina sonidos para aprender estas relaciones, perfeccionarlas e imitar los resultados. Normalmente, el ensamblaje de un buen modelo vocal puede solicitar una cierta capacitación, con muestras largas para indicar cómo habla una persona en particular. En los últimos días, sin embargo, ha aparecido algo nuevo: Microsoft Vall-Eenriquecido por Un documento de investigación (con ejemplos concretos) en una voz sintetizada que requiere solo unos segundos de audio de origen para generar una voz totalmente programable. Naturalmente, los investigadores y otros admiradores de IA querían saber si el modelo Vall-E ya se había puesto a disposición del público. La respuesta es no. Mientras tanto, es posible jugar con otro modelo si lo desea, llamado Tortoise. (El autor especifica que su nombre es tortuga porque es lento, lo que es cierto, pero funciona).
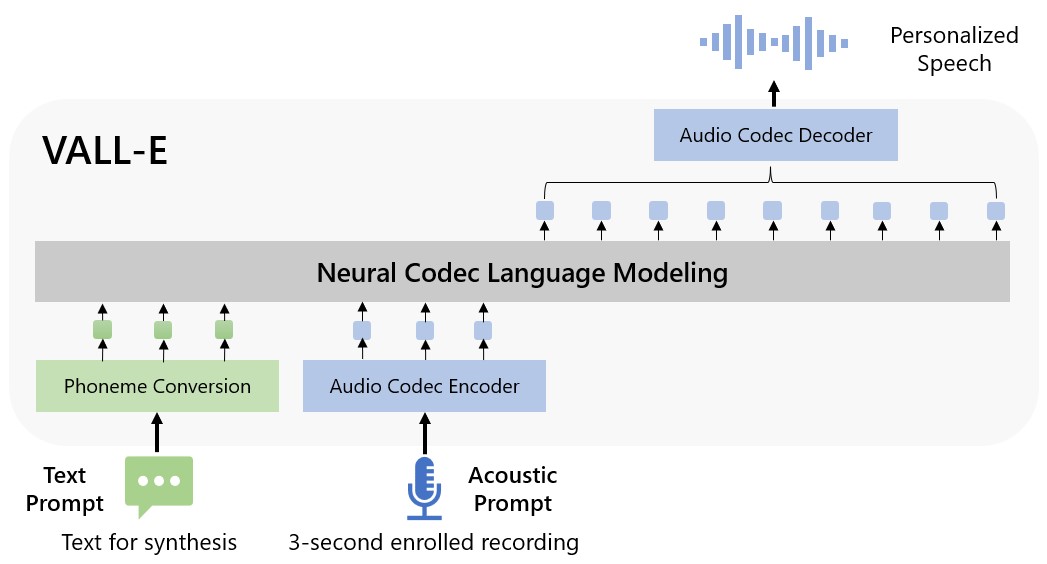
La descripción general de Vall-E. (Crédito: Vall-E / Microsoft)
Entrena su propia voz de IA con tortuga
Lo que lo hace interesante es que todos puedan entrenar al modelo en la voz de su elección simplemente descargando algunos clips de audios. Allá La página de Github de la solución indica Es necesario tener algunos clips de aproximadamente una docena de segundos. Luego guárdelos en un archivo .wav con calidad específica. ¿Cómo funciona? Gracias a un servicio en la nube desconocido: Google Colarb (o "Colabratorio"). Le permite escribir y ejecutar el código Python en su navegador sin ninguna configuración requerida, con acceso gratuito a GPU y intercambio fácil. El código que usted (o alguien más) puede escribir puede almacenarse en un cuaderno, que luego se puede compartir con usuarios que tienen una cuenta genérica de Google. Recurso compartido de tortuga está aquí.
La interfaz parece intimidante, pero no es tan mala. Debe estar conectado como usuario de Google, luego hacer clic en "Conectar" en la esquina superior derecha. Si este módulo no descarga nada de su unidad de Google, otros módulos pueden hacerlo. Tenga en cuenta que los archivos de audio que genera, por otro lado, se almacenan en el navegador pero se pueden descargar desde su PC. Pequeña aclaración que es importante: si alguien realiza un código escrito por otra persona, es posible que el usuario reciba mensajes de error, ya sea por una mala entrada o porque Google tiene un problema en el fondo, como no tener una GPU disponible. Todo esto es un poco experimental.
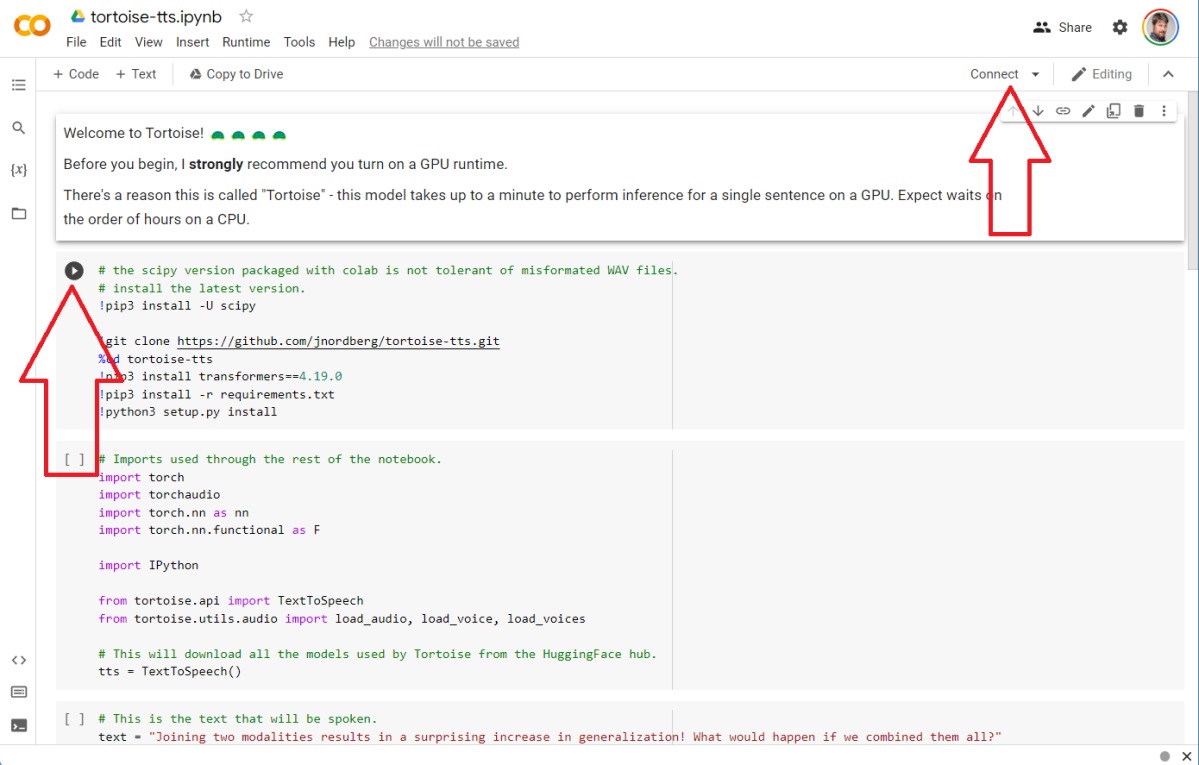
La colaboración de tortuga. Haga clic en el botón "Conectar" para comenzar, luego haga clic en el pequeño icono "Reproducir" junto a cada bloque de código a su vez. (Crédito: Mark Hachman / IDG)
Cada bloque de código tiene un pequeño icono de "juego" que aparece si pasa el mouse sobre él. Será necesario hacer clic en "Reproducir" en cada bloque de código para ejecutarlo, mientras se espera que cada bloque se ejecute antes de pasar a la ejecución del siguiente.
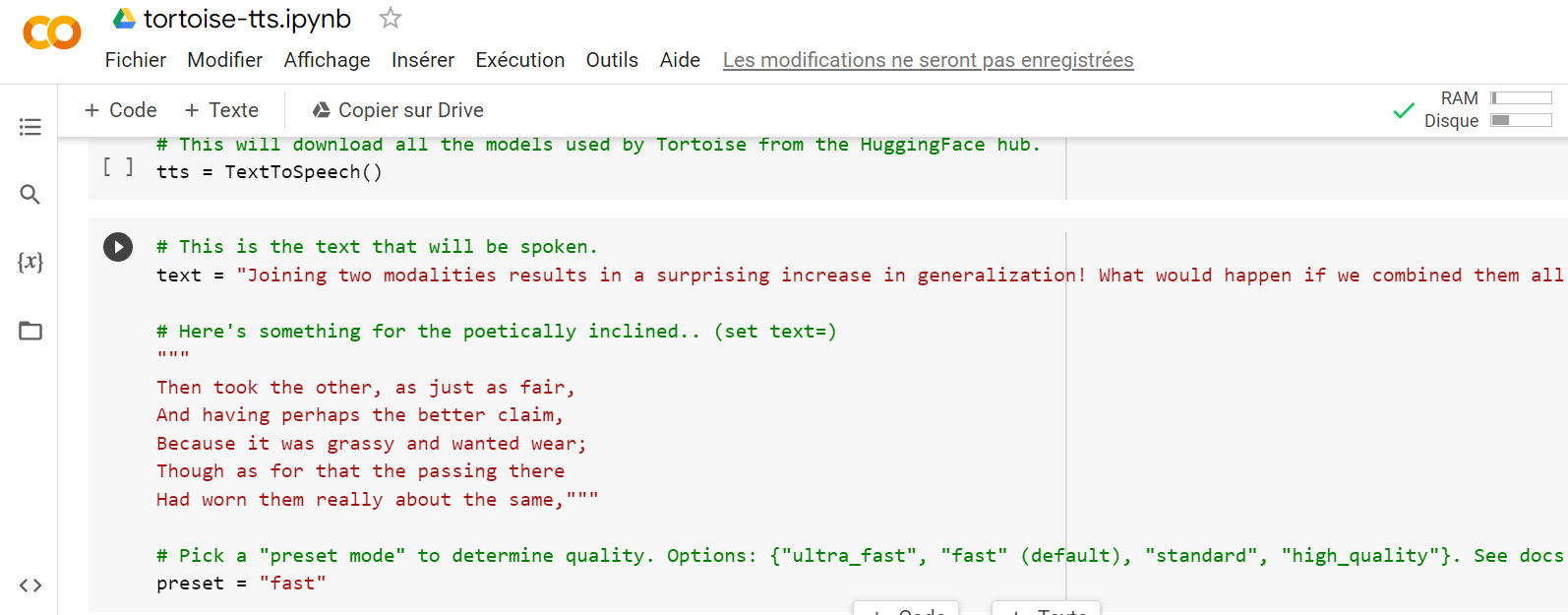
(Crédito: Colaboratorio)
Sin entrar en detalles, tenga en cuenta que el usuario puede ser modificado por el usuario, como el texto sugerido que queremos que el modelo pronuncie. Aproximadamente siete bloques a continuación, el usuario podrá formar el modelo, nombrarlo y luego descargar los archivos Audios. Una vez que se complete esta operación, simplemente seleccione el modelo de audio en el cuarto bloque, ejecute el código y luego configure el texto en el tercer bloque. Finalmente, este bloque de código debe ejecutarse. Si todo va según lo planeado, el resultado es una pequeña salida de audio de su muestra de voz. Funciona bastante bien, aún más cierto que la vida.
Otras noticias que te pueden interesar