
La guerra entre Databricks y Copo de nieve La batalla no se detiene y es en el terreno de los catálogos de datos donde se ha trasladado. Con motivo de su evento anual en Estados Unidos (del 3 al 6 de junio), el especialista en almacenamiento de datos en la nube presentó su catálogo de datos llamado Polaris Catalog. Competidor directo de Unity Catalog de Databricks, se centra en dos diferencias: es de código abierto y centraliza las tablas Apache Iceberg.
Una inteligente apertura de las tablas Iceberg
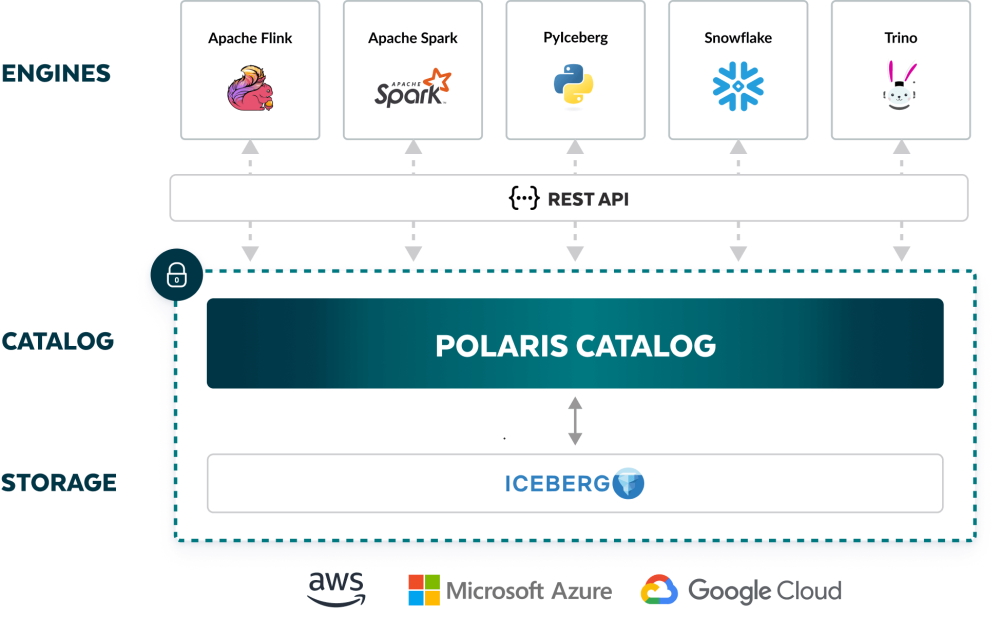
Para que conste, el catálogo de Unity está fechado en junio de 2022 y se ha actualizado con La adquisición de Okera en 2023. Se define como una oferta de gobernanza de datos que proporciona control de acceso, auditoría, catalogación y capacidades de búsqueda para datos en los espacios de trabajo de Databricks. Polaris Catalog tiene las mismas características con la incorporación de compatibilidad con las tablas Iceberg. "Con Polaris Catalog, los usuarios ahora tienen un lugar único y centralizado donde cualquier motor puede encontrar y acceder a las tablas Iceberg de una empresa con seguridad consistente e interoperabilidad completa y abierta", dijo la empresa en un comunicado. La oferta se basa en la API Rest de Iceberg que puede acceder y recuperar datos de cualquier motor, incluidos Apache Flink, Apache Spark, Dremio, Python y Trino, entre otros.
Snowflake detalla las asociaciones y compatibilidades con el catálogo Polaris. (Crédito de la foto: Snowflake)
Cabe señalar que el cambio a código abierto está previsto para los próximos 3 meses, asegura la empresa. Polaris Catalog se puede alojar en la AI Data Cloud de Snowflake (en versión preliminar por ahora) o en las instalaciones locales mediante contenedores como entornos Docker o Kubernetes. "Dado que la implementación del backend de Polaris Catalog será de código abierto, las empresas pueden cambiar libremente a otra infraestructura de alojamiento manteniendo todos los controles de seguridad y evitando la dependencia de un proveedor", afirmó la empresa.
Analistas críticos
Los analistas afirman que Polaris Catalog es, en efecto, una respuesta para “atraer una base de clientes más amplia y fomentar una comunidad vibrante a su alrededor”, señala Jayesh Chaurasia, analista de Forrester Research. Y añade: “La complejidad y diversidad de los sistemas de datos, junto con el deseo universal de las empresas de aprovechar la IA, requiere el uso de un catálogo de datos interoperable, que probablemente será de código abierto”. Esta naturaleza de código abierto es esencial porque “facilita la gestión de datos en distintas plataformas y entornos de nube”.
Otros consultores son más críticos, como Steven Dickens, vicepresidente de investigación de Futurum Group, que cree que el lanzamiento es un intento "desesperado" de ganarse la "buena voluntad" de los clientes y de la comunidad de código abierto. Cree que el paso al código abierto es el resultado de las deficiencias y limitaciones de Snowflake, entre ellas la escasa interoperabilidad, la dependencia de un proveedor, los costes exorbitantes, la falta de innovación y la dependencia de los socios. "Snowflake es notoriamente caro y su estructura de costes ha llevado a muchos clientes a buscar alternativas. Polaris Catalog puede verse como un último esfuerzo por retener a los clientes ofreciendo una alternativa de código abierto potencialmente más barata", explicó el consultor.
Otros rivales del código abierto
Jayesh Chaurasia y Steven Dickens también señalan que Polaris Catalog no es el único catálogo de datos de código abierto disponible en el mercado. Citan “Apache Atlas, Amundsen y DataHub de LinkedIn. Cada uno de ellos ofrece capacidades de descubrimiento de datos, gobernanza y gestión de metadatos”, recordó el analista de Forrester. Apache Atlas está diseñado para la gobernanza y el cumplimiento en entornos Apache Hadoop, proporcionando gestión de metadatos escalables, linaje y capacidades de gobernanza para Hadoop y tecnologías de big data relacionadas. Amundsen, que surgió de Lyft, tiene como objetivo mejorar la productividad de los analistas de datos, científicos e ingenieros indexando activos de datos (metadatos) y facilitando el descubrimiento y la exploración de conjuntos de datos en función del uso y la relevancia.
Por último, DataHub de LinkedIn, cuya arquitectura de metadatos en tiempo real admite diversos sistemas y entornos de datos mediante una integración conectable, también ofrece otra alternativa. "DataHub se centra en la ingestión de metadatos, la indexación, el descubrimiento y la gobernanza de los datos", afirmó Jayesh Chaurasia, y añadió que Amundsen y DataHub se han vuelto populares porque enfatizan la experiencia del usuario, el soporte para múltiples integraciones (tanto en tiempo real como por lotes) y las capacidades de descubrimiento de datos, impulsadas por la demanda de ofertas de gestión de datos eficientes.
Otras noticias que te pueden interesar