En el evento Re: Invent que tiene lugar en Las Vegas (del 2 al 6 de diciembre), AWS se esperaba en la IA. El proveedor de la nube ha respondido la llamada presentando características y herramientas para desarrolladores, incluidos los diversos anuncios.
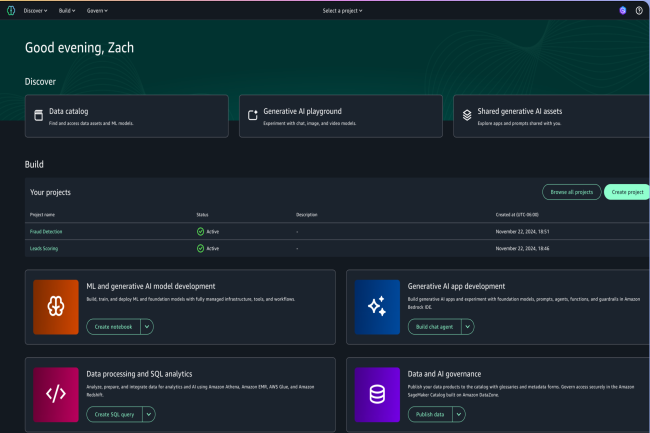
Sagemaker unificado estudio
Actualmente disponible en la vista previa, el SageMaker Unified Studio Service combina análisis SQL, procesamiento de datos, desarrollo de aplicaciones de IA, transmisión de datos, inteligencia de negocios e investigación analítica. "Sagemaker Unified Studio reúne las funciones de varios estudios autónomos que los especialistas en análisis y el uso de DataScientistic usan hoy en AWS, incluidas solicitudes autónomas y varias herramientas visuales", dijo Matt Garman, CEO de AWS. También presentó a Sagemaker Lakehouse, una base de datos compatible con las mesas Apache Iceberg. La oferta está disponible para todos ahora.
Sagemaker Unified Studio centraliza varias tareas para los desarrolladores. (Crédito de la foto: AWS)
Actualizaciones para el desarrollador Q
En 2023, Adam Selipsky, entonces CEO de AWS, presentó Amazon Q por primera vez, respuesta comercial a Copilot, el asistente generativo de IA pilotado por GPT de Microsoft. Este año, Matt Garman presentó actualizaciones para las capacidades de automatización de las tareas de codificación, en particular las funciones de automatización de las revisiones de código, las pruebas unitarias y la generación de documentación para el desarrollador Q. Según el gerente, estas adiciones reducirán la carga de trabajo de los desarrolladores y les ayudará a completar sus tareas de desarrollo más rápidamente.
Q desarrollador expande nuevas funciones. (Crédito de la foto: AWS)
Además, AWS ha presentado una vista previa de varias capacidades de traducción de código para Q, incluida la posibilidad de modernizar las aplicaciones de Windows a Linux .NET, la modernización del código de mainframe y ayudar a migrar instancias VMware. Matt Garman dijo que el desarrollador Q podría usarse para investigar los problemas operativos y resolverlos. Esta funcionalidad, actualmente en vista previa, podrá orientar al usuario en sus diagnósticos operativos y automatizar el análisis de las profundas causas de problemas en las cargas de trabajo.
Destilación de modelos e implementación de agentes para Bedrock
Durante su presentación, Matt Garman también enfatizó la roca madre, la plataforma de propietarios de AWS para la creación de modelos y aplicaciones generativas de IA. En particular, anunció el servicio de destilación de modelo administrado, primera actualización de Bedrock, disponible en la vista previa. Esta solución debe ayudar a las empresas a reducir sus costos operativos LLM. El proceso de destilación del modelo consiste en utilizar el conocimiento especializado de un LLM grande para crear un LLM más pequeño para un caso de uso específico. Las empresas a menudo eligen esta técnica para reducir los costos y la ejecución más rápida. Como explicó el CEO, "la destilación del modelo se ofrece como un servicio administrado, porque el proceso de destilación de un modelo más grande puede ser bastante pesado: los expertos de ML deben ocuparse de los datos de capacitación y el flujo de trabajo, ajustar los parámetros del modelo y monitorear el peso del modelo". El servicio funciona generando respuestas de los modelos de 'maestro' llamados y refinando un modelo de 'alumno' llamado SO. También utiliza técnicas de síntesis de datos para mejorar la respuesta de un modelo de 'maestro'.
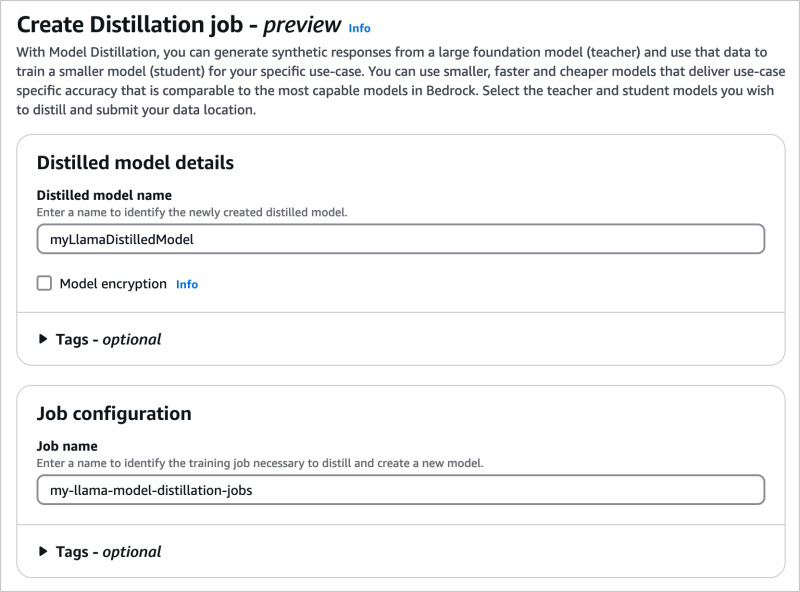
Es posible en Batedlrock para destilar LLM para que sean más pequeños y más especializados. (Crédito de la foto: AWS)
Además, el CEO ha presentado la función de verificación de razonamiento automatizado, actualmente en vista previa. Agregado a las barandillas, evita errores objetivos debido a alucinaciones, utilizando procesos de verificación y razonamiento algorítmicos matemáticos y lógicos para verificar la información generada por un modelo. Siguiendo las huellas de sus rivales, AWS ahora ha agregado la gestión de la colaboración de múltiples agentes en los agentes de roca madre en la vista previa. Entre las actualizaciones de base, aún podemos citar características destinadas a ayudar a las empresas a racionalizar las pruebas de aplicación antes de su implementación.
Modelos multimodales e instancias en Entrenium 2
Durante algún tiempo, y especialmente desde el mes de junio de este año, varios rumores han sugerido que WS se estaba preparando para comercializar un competidor de LLM de los de OpenAi, Xai y Google. Martes, Matt Garman dio a conocer una serie LLM llamada Novaque, según él, será al menos equivalente, si no mejor, que los modelos competidores, especialmente en términos de costo. La familia Nova incluye micro, una generación de texto de texto, lite, pro y primer texto. Todos los modelos están generalmente disponibles, con la excepción de First, que debería estar disponible para marzo. El proveedor indicó que también planeaba lanzar otros dos modelos en el próximo año bajo los nombres de Nova Speech to Speech y Nova a cualquiera.
Además de esta serie de actualizaciones de software para desarrolladores, AWS también comercializó su chip de Trainium2 Para mejorar el soporte para cargas de trabajo generativas de IA. Las instancias de EC2 alimentadas por AWS Entrenium2 ya están disponibles. Este chip de aceleración para las cargas de trabajo de IA y IA generativa se presentó por primera vez el año pasado. Según el proveedor, las instancias EC2 alimentadas por Entrenium2 son cuatro veces más rápidas, tienen cuatro veces más ancho de banda de memoria y tienen tres veces más capacidad de memoria que la generación anterior suministrada por los chips de Trainium1.
Otras noticias que te pueden interesar