En la gran familia de motores de búsqueda (Elasticsearch, Algolia, Typesense, Meilisearch y Solr), muy pocos actores franceses ocupan el primer plano: Exalead ha pasado a manos de Dassault y Qwant nunca ha podido competir en esta categoría. Un rival llamado Quickwit, con sede en San Francisco y fundado por franceses, pretende, sin embargo, cambiar las reglas del juego en el mercado de los motores de búsqueda e indexación para las empresas que explotan el big data (en particular, los logs) en un simple bucket de S3 o a mayor escala con Kafka o RedPanda. Creado en 2020 por Adrien Guillo, François Massot y Paul Masurel, Quickwit fue diseñado desde el principio para el big data. La historia comenzó hace poco más de tres años con una prueba de concepto capaz de competir con Elasticsearch, Splunk y Datadog en el mercado de la observabilidad. Desarrollado con el lenguaje de programación Rust, Quickwit utiliza el motor de búsqueda Tantivy, que, según François Massot, es el framework de búsqueda de código abierto más rápido que existe. El cofundador nos presentó su solución durante un IT Press Tour en Roma a principios de abril.
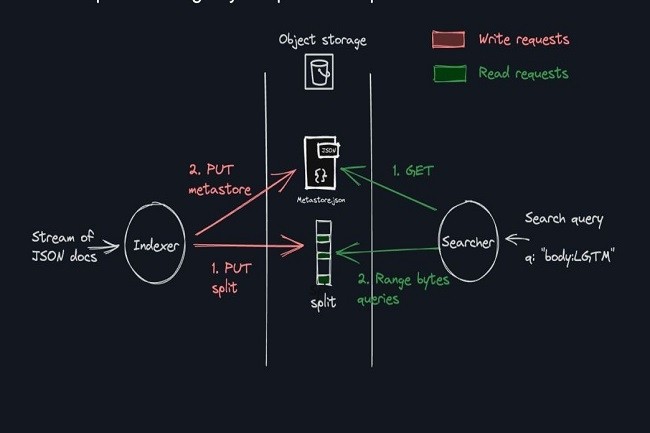
Sin embargo, el enfoque de Quickwit es muy diferente al de Elastic, con una arquitectura que separa el cálculo del almacenamiento. Si bien la solución es, sobre todo, un motor de búsqueda que se basa en un índice invertido, la start-up también ha implementado un sistema de almacenamiento optimizado para el objeto. Los datos resultantes de la indexación se almacenan en un sistema de almacenamiento local o se distribuyen en la nube (Amazon S3, GFS, Azure, Minio, Garage, IBM y nubes chinas) para optimizar los costos y ganar flexibilidad. Recordemos que en Elasticsearch, los datos se almacenan en segmentos, que luego forman parte de fragmentos (instancias). Estos últimos, así como sus réplicas, se distribuyen en diferentes nodos de datos físicos en el clúster. Cada nodo del clúster es responsable tanto del cálculo como del almacenamiento de los datos del índice.
Compatible con Kafka, Pulsar y Google Pub/Sub
Para los metadatos (información sobre índices, esquemas y otros detalles relevantes), Quickwit utiliza un sistema de almacenamiento independiente, que se basa en PostgreSQL, Aurora u otra base de datos similar. En el lado de cómputo, los nodos de índice son responsables de procesar e indexar los datos entrantes. Estos nodos no contienen los datos reales, pero realizan los cálculos necesarios para la indexación. Además, los nodos de búsqueda procesan las consultas de búsqueda y recuperan datos del almacenamiento de índice. Al igual que los nodos de índice, no tienen estado y no almacenan ningún dato. Quickwit admite el escalamiento horizontal de los nodos de búsqueda, lo que permite agregar o eliminar nodos según los requisitos de la carga de trabajo. Esta flexibilidad contribuye a la escalabilidad general del sistema.
Quickwit admite diferentes fuentes de datos: Kafka, Pulsar, Google Pub/Sub... y ofrece su propia API de ingesta. También es posible utilizar la oferta con un almacén de datos en S3. Los clientes que ya tienen sus datos en Kafka o RedPanda se benefician de una integración nativa en Quickwit, no es necesario copiar/replicar sus datos. En cuanto a la interfaz de usuario, la elección es bastante amplia con el soporte de Jaeger o Grafana.
Más de 200 clientes hasta la fecha
Como ejemplo, François Massot nos contó que un cliente especializado en criptoactivos había migrado de OpenSearch (fork de Elastic y Kibana) a su solución y había logrado dividir los costos de computación por 5 y de almacenamiento por 2, al tiempo que aumentaba sus capacidades de retención por 10. El clúster puesto en servicio digirió 40 PB de datos, incluidos 7,5 PB en S3 en más de 500 instancias. Para la hoja de ruta para 2024 y más allá, Ingenio rápido está trabajando en la posibilidad de una migración sin problemas desde Búsqueda abiertaConsultas basadas en canalizaciones de tipo SPL de Splunk y Un motor almacenamiento para datos de series temporales. Concluiremos señalando que Ingenio rápido trabaja directamente y con socios como proveedores de servicios en la nube. La versión comunitaria está disponible a través de su distribución de código abierto. La puesta en marcha reclamos Hoy Más de 200 clientes.
Otras noticias que te pueden interesar