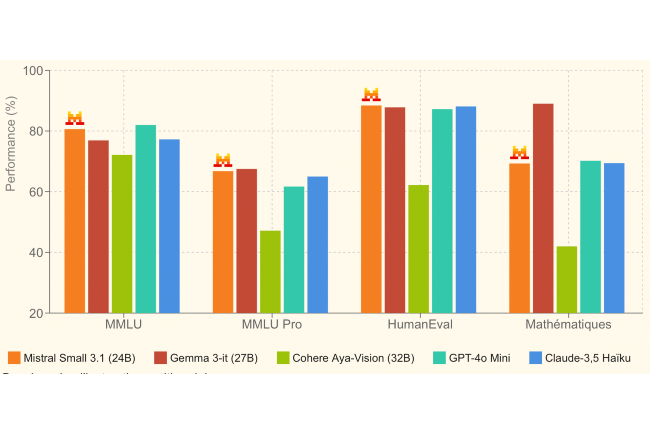
Los pequeños modelos tienen la Costa y la IA Mistral tienen la intención de conquistar este mercado con su último SLM Small 3.1. Desarrollado a partir del modelo Small 3, lanzado en enero pasado, esta versión de 24 mil millones de parámetros ofrece un rendimiento textual reforzado, una mejor comprensión multimodal y una ventana contextual ampliada, capaz de contener hasta 128,000 tokens. En Su comunicado de prensaLa nueva empresa explica que Small 3.1 compite en términos de rendimiento con otros modelos competidores.
Un modelo efectivo para diferentes campos
En esta área, se mide a Gemma 3 recientemente presentado por Google Y GPT-4O Mini de OpenAi. El SLM de Mistral se distingue por su velocidad, generando hasta 150 tokens por segundo, una reactividad similar a la competencia. Operando en una tarjeta gráfica RTX 4090 o una Mac con 32 GB de RAM, Small 3.1 es perfectamente adecuado para entornos móviles. También es muy efectivo para los asistentes virtuales, donde la capacidad de respuesta y la precisión son esenciales.
Mistral dijo en un artículo de blog que Small 3.1 es versátil y personalizable. Se puede utilizar para "verificar documentos, diagnósticos, procesamiento de imágenes, inspección visual para controles de calidad, detección de objetos en sistemas de seguridad, atención al cliente basada en imágenes y asistencia de uso general".
Acceso inmediato para desarrolladores
Distribuido bajo la licencia Apache 2.0, Small 3.1 es explotable libremente por las empresas y la comunidad de código abierto. Ya está disponible en la cara abrazada en dos variaciones: instrucción Mistral Small 3.1 Base y Mistral Small 3.1. También se puede acceder al modelo a través de la AI AI AI, así como en Google Cloud Vertex AI. En las próximas semanas, se integrará en la fundición de Nimvia y Azure Ai de Microsoft Nvidia y Azure Services.
Otras noticias que te pueden interesar