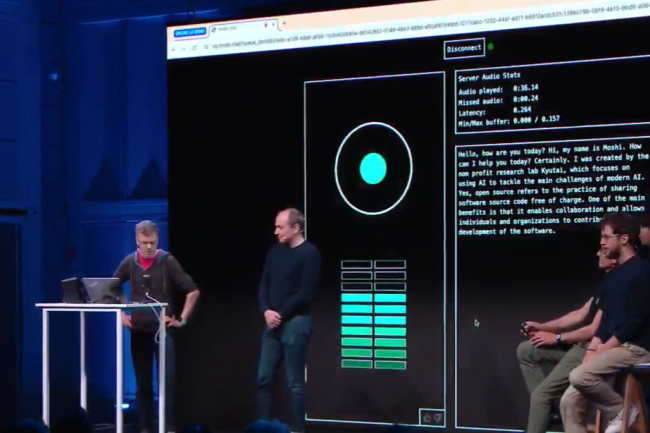
El gran baño para Kyutai. Precisamente este 3 de julio este laboratorio de investigación sin ánimo de lucro especializado en GenAI - Fruto de la fusión entre Iliad, CMA-CGM y Schmidt Futures Kyutai, la empresa tecnológica que se ha anunciado el pasado 17 de noviembre, ha presentado su primer trabajo. En este caso, un prototipo de asistente de voz con IA, llamado Moshi (moshi moshi significa hola en japonés) desarrollado por un equipo de 8 investigadores y basado en la infraestructura en la nube de Scaleway, que incluye un centenar de aceleradores GPU de Nvidia. “Moshi es muy prometedor y tiene un gran potencial para cambiar la forma en la que nos comunicamos con las máquinas y la accesibilidad para las personas con discapacidad”, afirma Patrick Pérez, CEO de Kyutai.
Con motivo de este anuncio, se realizó una demostración para demostrar las capacidades de Moshi. Más allá del desempeño del asistente al iniciar, continuar y cerrar una conversación con un humano, aún notaremos una impresión bastante inquietante, incluso perturbadora, de que Moshi interrumpe a su interlocutor. Una característica que, sin embargo, parece asumida: para hacer más creíble el intercambio entre el agente y un humano, se han integrado muchos parámetros como la capacidad de dudar, de susurrar, de hablar con acento o con tono... pero también de interrumpir o incluso hablar al mismo tiempo que un humano. De hecho, se han tenido en cuenta elementos paralingüísticos (emoción, tono...) para influir y proporcionar dinámica conversacional.
70 emociones y formas de hablar apoyadas por Moshi
Como parte de su trabajo, Kyutai desarrolló un procesamiento de datos multimodal y multistream, capacidades de conversión de voz a texto y de entrenamiento. Se utilizó un gran volumen y diversidad de datos para entrenar a Moshi con un LLM 7B (Helium). Las capacidades de procesamiento y generación de audio para enseñar al asistente a hablar en el momento adecuado y qué decir también fueron objeto de ajustes específicos (ajuste fino). Se utilizó un diálogo sintético (para el estilo oral) acoplado a un motor de conversión de voz a texto desarrollado internamente en el que se entrenaron los modelos de datos. En cuanto a la voz en sí, Kyutai recurrió a los servicios de un artista que alimentó el modelo con una gran cantidad de diálogos, para un total de 70 emociones o formas de hablar (murmullos, miedo, vacilaciones, etc.). También se trabajó en la latencia para alcanzar los 200 milisegundos, cerca de una conversación entre dos humanos. Finalmente, también se ha trabajado en el código y el peso de los modelos para poder ejecutarse localmente, por ejemplo en un Macbook Pro.
Kyutai también planea compartir de forma libre y gratuita todo el conocimiento, la documentación técnica y los modelos, así como el código de su asistente de voz de inteligencia artificial Moshi, en particular para fines de prueba y estudio.
Otras noticias que te pueden interesar