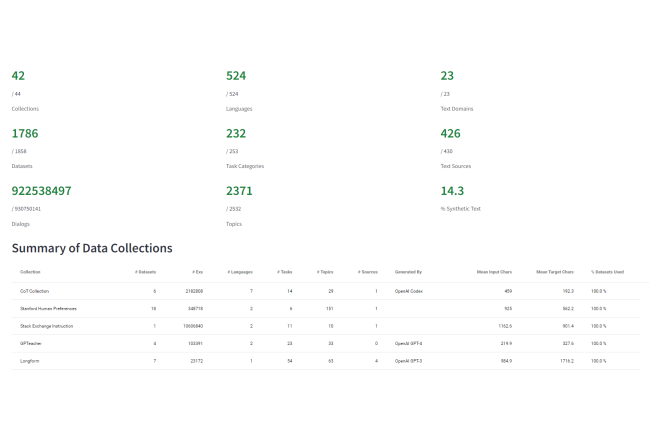
La cuestión del origen de los datos utilizados para entrenar modelos generativos de IA surge periódicamente en las conversaciones con los responsables de TI. Se plantean problemas de seguridad, confidencialidad y cumplimiento de las licencias. Expertos en aprendizaje automático y derecho del MIT, Cohere y otras 11 organizaciones, incluidas la Facultad de Derecho de Harvard, la Universidad Carnegie Mellon y Apple, han desarrollado una herramienta llamada Explorador de procedencia de datos.
Permite a investigadores, periodistas y cualquier otra persona buscar miles de bases de datos de entrenamiento de IA y rastrear la "genealogía" de los conjuntos de datos más utilizados. La idea es proporcionar una forma de explorar el mundo, a veces confuso, de los datos de entrenamiento utilizados para desarrollar la IA generativa. En una declaración oficial que anuncia Data Provenance Explorer, el equipo detrás de él describe una "crisis de transparencia de datos" que podría complicar el desarrollo y el uso comercial de sistemas generativos de IA.
Falta de licencia de datos de crowdsourcing
"Los agregadores de datos compartidos como GitHub, Papers with Code y muchos modelos de lenguaje grande (LLM) de acceso abierto entrenados con los datos de estos agregadores tienen un porcentaje extremadamente alto de datos sin licencia... que van del 72% al 83%", dijo el grupo. . "Además, las licencias asignadas por agregadores populares a menudo permiten un uso más amplio que la intención original expresada por los autores de un conjunto de datos". Según Kathy Lange, directora de investigación de IDC, “la industria parece muy consciente de la necesidad de desarrollar la IA de manera responsable. La loca carrera por implementar IA generativa ha generado interés público en el uso seguro y legal de los datos”, dijo. “Comprender de dónde provienen los datos, cómo se recopilaron, procesaron y transformaron puede afectar la confianza en los resultados de los modelos de IA”, añadió el consultor.
“Los proveedores de IA que prioricen el origen de los datos tendrán una ventaja de mercado para los clientes que exigen iniciativas de transparencia, responsabilidad y cumplimiento. En cierto modo, los datos de la IA se han convertido nada menos que en un campo de batalla. Kathy Lange recordó la reciente disponibilidad de la herramienta Nightshade, que modifica sutilmente el arte digital de maneras que confunden a los creadores de IA que intentan utilizar obras protegidas por derechos de autor como datos de entrenamiento. Además, los autores y otros titulares de derechos de autor han comenzado a presentar demandas contra el uso de sus obras en el entrenamiento de la IA generativa. La actriz y autora Sarah Silverman se encuentra entre quienes demandaron a OpenAI por este motivo. Sin embargo, por el momento, el panorama jurídico de estas denuncias sigue siendo oscuro en muchos aspectos.
Otras noticias que te pueden interesar