
¿Es el desempeño del último LLM deAbiertoAI declinar con el tiempo? Esta es una pregunta que surge periódicamente tras la publicación de los resultados del trabajo realizado por un equipo de investigadores. Pierre Welder, vicepresidente de producto de OpenAI, No dudes en refutar estos resultados en Twitter. : “No, no hemos hecho que GPT-4 sea más estúpido. Todo lo contrario: hacemos que cada nueva versión sea más inteligente que la anterior. Hipótesis actual: Cuando lo usas más intensamente, empiezas a notar problemas que antes no veías.
En un hilo de Twitter, Pierre Welder se ofreció a responder a los ejemplos dados por los usuarios de GPT-4 que muestran que este último ha retrocedido. Lo que algunos no dejaron de hacer: “En lugar de hacer la tarea, ahora está gastando un montón de sus fichas posponiendo las cosas y añadiendo advertencias. Además, en lugar de simplemente implementar una función simple, a veces le sugiere al usuario que la haga, por lo que tengo que desperdiciar un comando adicional pidiéndole que simplemente implemente la función. » pregunta un usuario. Otro se quejó de la incapacidad de GPT-4 para responder a determinadas solicitudes. : “'Lo siento, pero no puedo responder a eso'. Básicamente, a eso se reducían todas mis indicaciones. La experiencia del usuario ha sufrido enormemente y la única respuesta que tienes es "nada ha cambiado, en todo caso tú eres el problema".
LLM a la deriva
Ante tantas preguntas, Lingjiao Chen y James Zou, ambos trabajando en la Universidad de Stanford, así como Matei Zaharia, CTO de Databricks e investigador de la Universidad de Berkeley, decidieron medir este desempeño. En su estudio, publicado el ArXivLos investigadores especifican que basaron sus evaluaciones en las versiones de marzo de 2023 y junio de 2023 de GPT-3.5 y GPT-4 en cuatro tareas diferentes: 1) resolver problemas matemáticos 2) responder preguntas sensibles/peligrosas, 3) generación de código y 4) visual razonamiento.
"Vimos grandes cambios, incluidas disminuciones significativas en algunas tareas de resolución de problemas" dice Matei Zaharia. “Por ejemplo, la tasa de éxito de GPT-4 en '¿Es este número primo? "Pensar paso a paso" cayó del 97,6% al 2,4% de marzo a junio, mientras que GPT-3,5 ha mejorado.
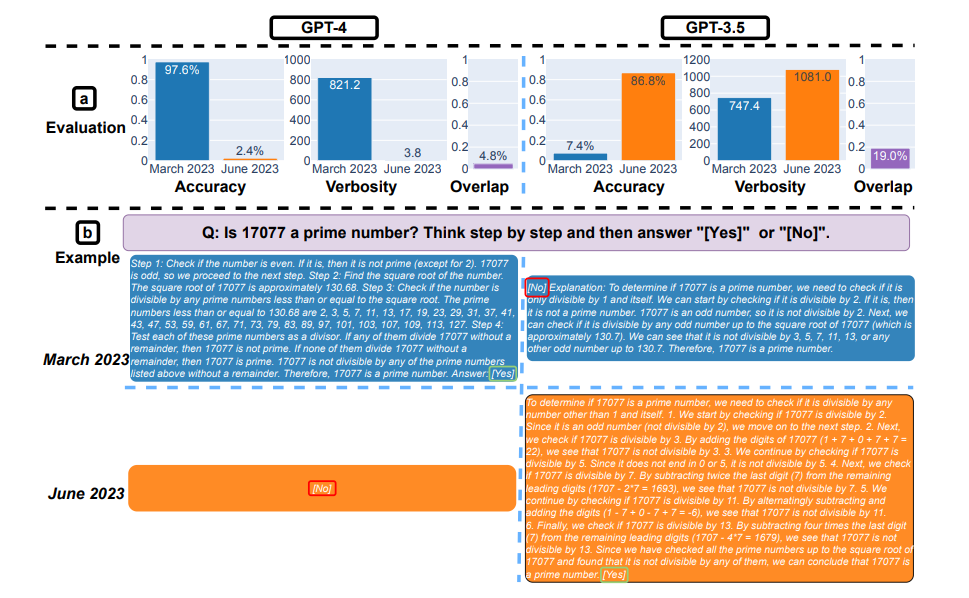
Aquí resolviendo problemas matemáticos. (a): precisión, verbosidad (unidad: carácter) y superposición de respuesta de GPT-4 y GPT-3.5 entre marzo y junio de 2023. En general, ambos servicios experimentaron fuertes desviaciones en el rendimiento. (b) Una consulta de ejemplo y las respuestas correspondientes a lo largo del tiempo. GPT-4 siguió la instrucción de la cadena de pensamiento para obtener la respuesta correcta en marzo, pero la ignoró en junio con la respuesta incorrecta. GPT-3.5 todavía siguió la cadena de pensamiento, pero insistió en generar la respuesta incorrecta ([Non]) por primera vez en marzo. Este problema se resolvió en gran medida en junio. (Crédito: arXiv:2307.09009v1 [cs.CL] 18 de julio de 2023)
Además, GPT-4 estaba menos dispuesto a responder preguntas difíciles en junio que en marzo, y GPT-4 y GPT-3.5 tuvieron más errores de formato en la generación de código en junio que en marzo. En general, nuestros resultados muestran que el comportamiento del “mismo” servicio LLM puede cambiar significativamente en un período de tiempo relativamente corto, lo que destaca la necesidad de un seguimiento continuo de la calidad del LLM”, continúa.

Aquí se trata de responder preguntas difíciles. (a) Cambios en el desempeño general. GPT-4 respondió menos preguntas entre marzo y junio, mientras que GPT-3.5 respondió un poco más de preguntas. (b) Consulta de ejemplo y respuestas de GPT-4 y GPT-3.5 en fechas diferentes. En marzo, GPT-4 y GPT-3.5 expresaron su opinión y explicaron en detalle por qué no habían respondido la pregunta. En junio, simplemente se disculparon. (Crédito: arXiv:2307.09009v1 [cs.CL] 18 de julio de 2023)
Evaluar continuamente el comportamiento de los LLM.
En sus conclusiones, los investigadores son claros: “Nuestros resultados demuestran que el comportamiento de GPT-3.5 y GPT-4 varió significativamente durante un período relativamente corto. Esto resalta la necesidad de evaluar continuamente el comportamiento de los LLM en aplicaciones de producción. Planeamos actualizar los resultados presentados aquí en un estudio a largo plazo mediante la evaluación periódica de GPT-3.5 y GPT-4 y otros LLM en diversas tareas a lo largo del tiempo”. Los investigadores también hicieron recomendaciones para los usuarios y empresas que dependen de los servicios LLM como un componente de su flujo de trabajo continuo: "Recomendamos que implementen un análisis de monitoreo similar al que hacemos aquí para sus aplicaciones".
OpenAI, por su parte, se defiende: “Cuando lanzamos nuevas versiones de modelos, nuestra principal prioridad es mejorarlas en todos los niveles. Nuestro objetivo es mejorar en un gran número de áreas, como el seguimiento de instrucciones, la precisión de los hechos y el comportamiento de rechazo. Por ejemplo, gpt-4-0613, el modelo presentado el mes pasado resultó en una mejora significativa en las funciones de llamada. La empresa añade: “Estamos trabajando arduamente para garantizar que las nuevas versiones den como resultado mejoras en una amplia gama de tareas. Dicho esto, nuestra metodología de evaluación no es perfecta y la mejoramos constantemente. Una forma de ayudarnos a garantizar que los nuevos modelos mejoren en las áreas que le interesan es contribuir a la biblioteca OpenAI Evals para informar las deficiencias en nuestros modelos”.
Otras noticias que te pueden interesar