Lo mejor es a menudo el enemigo del bien. Este es también el caso en el universo de LLM Según la investigación En el que participaron varios académicos de Carnegie Mellon, Stanford, Harvard y Princeton. Si bien se adquiere comúnmente que los grandes modelos de lenguaje previamente capacitado en tokens cada vez más importantes conducen a un mejor rendimiento, la realidad parece mucho más contrastante.
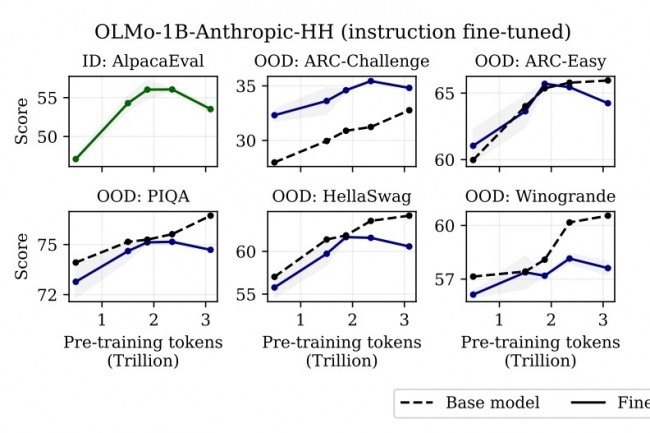
En su estudio, los investigadores tienen efectiva esta hipótesis al demostrar que un pretrentador prolongado puede, por el contrario, hacer que los modelos sean más difíciles de refinar, llegando a causar un deterioro en el rendimiento final. Este fenómeno, descrito como "sobreentrenamiento catastrófico" proviene del interrogatorio de una estrategia hasta ahora adoptada en gran medida que consiste en aumentar el rendimiento de los modelos con una previamente remediada. Sin embargo, esto no siempre parece ser el caso: por ejemplo, el modelo OLMO-1B de antrópico pre-coachado en 3 tokens trillones de cables de acuerdo con los investigadores para un rendimiento más bajo de más del 2 % a los del mismo modelo que ha usado 2.3 trillones en muchos puntos de referencia estándar de LLM.
"Gracias a las experiencias controladas y un análisis teórico, mostramos que los resultados catastróficos de sobreentrenamiento de un aumento sistemático en la sensibilidad general de los parámetros previamente capacitados a las modificaciones, que incluyen, pero sin limitarse a él, al ajuste fino", se pueden leer en el informe. "Nuestros resultados requieren una reevaluación crítica del diseño del pre-entrenamiento que tiene en cuenta la adaptabilidad posterior del modelo", dijeron los investigadores.
Otras noticias que te pueden interesar