Una publicación de blog Publicado el miércoles Por Cloudflare revela que un error de software ha llevado a la pérdida de alrededor del 55 % de los registros que se habrían enviado a los clientes durante un período de las 3:30 a.m. del 14 de noviembre. La compañía explica que cada parte de su red global de servicios genera periódicos de eventos que contienen metadatos detallados en sus actividades. Por ejemplo, cada solicitud enviada a la Red de difusión de contenido del proveedor (CDN) crea un periódico. Este último hace que estos registros estén disponibles para sus clientes, que pueden usarlos de diferentes maneras, especialmente para el cumplimiento, la observabilidad y la contabilidad. La compañía dijo que durante un día normal, envía alrededor de 4.5 billones de registros a sus clientes. El problema apareció como resultado de una modificación realizada en un sistema llamado Logpush, que recopila periódicos individuales de la red de servidores de CloudFlare en lotes y los envía a los clientes. Aunque este último puede recibir sus registros directamente de cada servidor, la mayoría de ellos eligen no hacerlo.
"Por analogía, imagine que el servicio postal suena en su puerta una vez para cada letra en lugar de una vez para cada paquete de cartas", dijo Cloudflare en su boleto. "Con miles o millones de letras por segundo, el número de transacciones distintas que esto implicaría se vuelve prohibitiva. Cuando la compañía agregó la administración de otro conjunto de datos en Logpush, también tuvo que agregar otra configuración a un componente llamado LogfwDR para indicar al sistema en que los periódicos del cliente tenían que ser transmitidos al nuevo flujo. Un error en el sistema envió un configuración vacía a logfwwDR, diciendo que no transfiría lo que tiene el control de los clientes, que no se transfirió a los periódicos de los clientes, lo que tenía el control de los clientes. se vio rápidamente y la modificación se canceló en menos de cinco minutos.
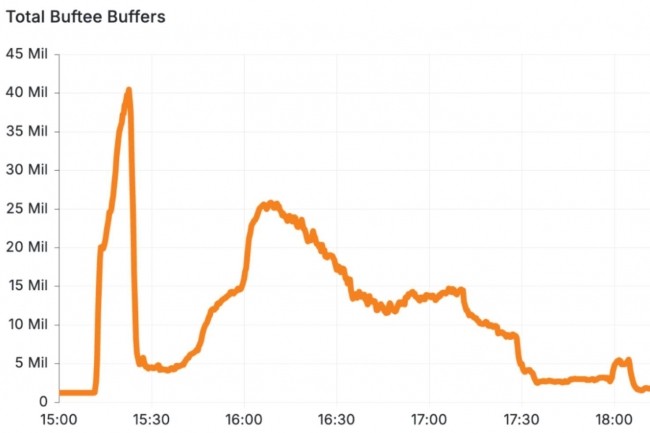
Un error de configuración de solo 5 minutos
Sin embargo, que había sido diseñado como un dispositivo de seguridad para lidiar con este tipo de problema que se volvió contra ellos. Cuando la configuración LogFWDR no estaba disponible, el sistema de seguridad envió periódicos a todos los clientes. En este caso, este problema de cinco minutos causó un pico masivo en el número de registros que se enviaron, sobrecargando el búfer, Bufftee y lo hacía inoperativo. Bufftee proporciona amortiguadores para cada tarea de logpush para que la falla del tratamiento de la tarea de un cliente no afecte la progresión de los demás. Contenía medidas de protección para evitar esta avalancha, pero no habían sido configuradas, dijo Cloudflare.
"Un error de configuración temporal de solo cinco minutos creó una sobrecarga masiva que nos llevó varias horas repararla y volver a colocarnos en el blog". Debido a que nuestros topes no estaban configurados correctamente, los sistemas subyacentes estaban tan sobrecargados que no podíamos interactuar con ellos normalmente. El reinicio y reinicio completo fue necesario ". Para evitar que estos problemas se reproduzcan," creamos alertas para garantizar que sea imposible perderse estos errores de configuración particulares, y también atacamos el error específico y las pruebas asociadas que desencadenaron este incidente. »»
Otras noticias que te pueden interesar