Con sus chips, Cerebras se invita a la carrera por la IA generativa
hace 2 años
Especializada en la producción de chips y sistemas de IA, la joven empresa emergente Cerebras ha desarrollado y capacitado siete modelos principales de lenguaje para IA generativa en modo de código abierto.
Una empresa emergente prometedora fundada en 2015 e históricamente especializada en chips y sistemas de IA, Cerebras Systems ha recaudado $ 720 millones desde su creación, incluidos $ 250 millones en 2021. Co-creada por Andrew Feldman, su CEO y ex director de SeaMicro (vendido a AMD en 2012 por 355 M$) Sean Lie, arquitecto jefe de hardware, el joven retoño ha multiplicado sus productos desde su creación. Después del chip WSE más grande del mundo, un procesador creado para el aprendizaje profundo en 2019 y, en noviembre pasado, una supercomputadora llamada Andrómeda, Cerebras anuncia que ha capacitado y promovido a la comunidad de investigación siete modelos principales basados en el lenguaje (LLM) para el desarrollo generativo. AI.
"Cerebras-GPT tiene tiempos y costos de capacitación más rápidos y consume menos energía que cualquier otro modelo disponible en la actualidad", explicó Cerebras. El proveedor también destaca que su tecnología es “abierta y accesible”, y se ofrece bajo la licencia Apache 2.0. “Entrenamos todos los modelos Cerebras-GPT en un clúster de Andrómeda a escala de oblea CS-2 de 16x. Este clúster hizo posible realizar todos los experimentos rápidamente, sin la ingeniería de sistemas distribuidos tradicional y el ajuste de modelos paralelos necesarios en los clústeres de GPU. Más importante aún, permitió a nuestros investigadores centrarse en el diseño de ML en lugar del sistema distribuido”, dijo la firma.
7 LLM capacitados en 16 sistemas CS-2
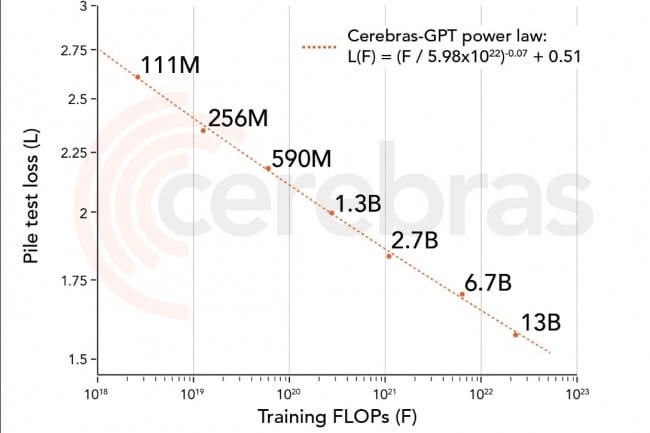
Estos nuevos LLM se capacitaron con 16 sistemas CS-2 del supercluster Andromeda AI que se ejecutan en el último chip WSE-2 del proveedor, diseñado específicamente para ejecutar software AI. Están disponibles en GitHub y Hugging Face. Cada uno de estos diferentes modelos tiene un número particular de parámetros: 111 millones, 256 millones, 590 millones, 1.300 millones, 2.700 millones, 6.700 millones y 13.000 millones. El entrenamiento de estos modelos normalmente tomaría varios meses, pero Cerebras dijo que la velocidad de los sistemas Cerebras CS-2 en Andromeda, combinada con una arquitectura única, ha reducido ese tiempo a solo unas pocas semanas. Como era de esperar, como parte de su comparación interna, Cerebras destacó sus principales LLM frente a OpenAI GPT-4, Deepmind Chinchilla, Meta OPT y Pythia.
Para aprovechar esto, la compañía debe, por tanto, dotarse de sistemas de IA, lo que parece ser una muy buena estrategia para el grupo: resaltar las capacidades del modelo que se ejecuta en sus propios sistemas y aprovechar este desempeño de los abiertos. modelo de origen disponible para todos ellos debe por lo tanto recurrir a los equipos y materiales del proveedor. Si es necesario, el proveedor que definitivamente ha pensado en todo ofrece a las empresas ejecutar su LLM en... su nube. "Creemos que la capacidad de entrenar fácilmente modelos grandes es un factor clave para la comunidad en general, razón por la cual hemos hecho que Wafer-Scale Cluster esté disponible en la nube a través de Cerebras AI Model Studio". . Una intención loable pero que, a diferencia de Cerebras-GPT, esta vez está dando sus frutos.
Si quieres conocer otros artículos parecidos a Con sus chips, Cerebras se invita a la carrera por la IA generativa puedes visitar la categoría Otros.
Otras noticias que te pueden interesar