Para ayudar a las empresas a resolver problemas de rendimiento con estos sistemas, AWS están trabajando en el desarrollo de un depurador de bases de datos basado en un LLM interno. "Llamado Panda, el marco de depuración fue diseñado para funcionar de manera similar al de un DBE (ingeniero de bases de datos)", escribió el proveedor en un blogagregando que solucionar problemas de rendimiento en una base de datos puede ser "notoriamente difícil".
A diferencia de los administradores de bases de datos, que son responsables de gestionar múltiples bases de datos, la función de los DBE es diseñar, desarrollar y mantener bases de datos. De hecho, Panda proporciona una base contextual para que los LLM previamente capacitados generen recomendaciones de solución de problemas más "útiles" y "contextualizadas", explicaron los investigadores.
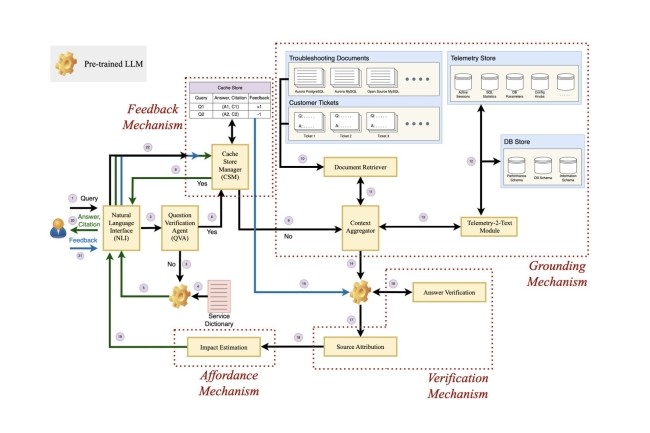
Componentes y arquitectura de Panda.
El marco incluye cuatro elementos clave: anclaje, verificación, accesibilidad y retroalimentación. El primero se describe como la capacidad del modelo para verificar la respuesta generada utilizando fuentes relevantes y producir la cita con su resultado para que el usuario final pueda verificarla. "Entonces, la accesibilidad puede describirse como la capacidad del marco para informar al usuario de las consecuencias de la acción recomendada sugerida por un LLM mientras resalta explícitamente las acciones de alto riesgo, como DROP o DELETE", dijeron investigadores de otros lugares. En cuanto al componente de retroalimentación de Panda, "permite que el depurador basado en LLM acepte comentarios de los usuarios y los tenga en cuenta al generar respuestas", según los investigadores.
Estos cuatro componentes, a su vez, conforman la arquitectura del depurador, que incluye el Agente de verificación de preguntas (QVA), mecanismos de acoplamiento, verificación, retroalimentación y accesibilidad. Mientras que el agente QVA identifica y filtra consultas irrelevantes, el mecanismo de anclaje incluye un extractor de documentos, Telemetría-2-texto y un agregador de contexto para proporcionar más contexto a un mensaje o consulta. "El mecanismo de verificación incluye verificación de respuesta y atribución de fuente", dijo AWS, y agregó que todos estos mecanismos, así como la retroalimentación y la accesibilidad, funcionan detrás de escena de una interfaz. en lenguaje natural con el que interactúa el usuario empresarial.
Panda contra el modelo GPT-4 de OpenAI
AWS también enfrentó a Panda con el modelo GPT-4 de OpenAI, que actualmente sustenta ChatGPT. "Cuando se pide a ChatGPT que responda preguntas sobre el rendimiento de la base de datos, a menudo recibimos recomendaciones "técnicamente correctas" pero muy "vagas" o "genéricas", generalmente inútiles y poco fiables para los ingenieros de bases de datos experimentados", especifica el proveedor, presentando un resultado obtenido durante la solución de problemas de una base de datos Aurora PostgreSQL. Según el artículo, para este experimento, AWS reunió a un grupo de ingenieros de bases de datos de tres niveles de habilidad y la mayoría de ellos se pronunció a favor de Panda. Además, los investigadores dicen que aunque en su experimento utilizaron Panda en bases de datos en la nube, el depurador se puede extender a cualquier sistema de base de datos.
Otras noticias que te pueden interesar