AWS pone su servicio Prime Video a prueba de la ingeniería del caos
hace 5 años
El principio de la ingeniería del caos es provocar fallas en los sistemas informáticos de producción para probar su resistencia de manera más efectiva. Después de Netflix, Amazon Web Services muestra cómo aplica su servicio de video bajo demanda.
Al igual que Netflix, AWS está probando la resistencia de su servicio de transmisión de video Prime introduciendo turbulencias en sus sistemas de producción de manera controlada. Este es el principio del caos de ingeniería. Esta disciplina implica poner un sistema a prueba para generar confianza en su capacidad para resistir fallas durante la producción. Se lo debemos principalmente a Netflix, que experimentó con su herramienta Chaos Monkey hace varios años. Esto cerró de forma pseudoaleatoria un servidor de su servicio de vídeo online con el fin de proporcionar a sus equipos informáticos una incidencia a resolver en las mejores condiciones de intervención posibles, es decir, en horario laboral a una hora planificada con antelación. El objetivo es poder aprender de él para facilitar el manejo de incidentes reales ocurridos en un contexto más delicado.
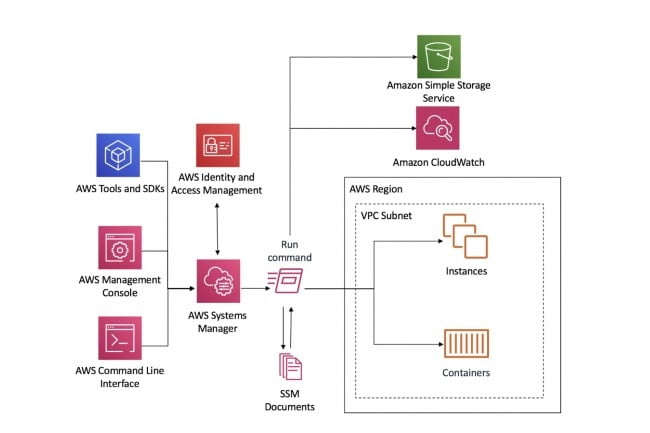
"La ingeniería del caos requiere la adopción de prácticas para identificar de manera proactiva las interacciones en los sistemas distribuidos y las fallas asociadas, así como la implementación y validación de contramedidas", recuerda AWS en una publicación del 18 de agosto de 2020 donde el operador de servicios en la nube presenta un enfoque para la inyección de fallas ( a través de AWS Systems Manager, SSM Agent) en sistemas que utilizan Elastic Compute Cloud (EC2) y Elastic Container Service (ECS). Este enfoque está asociado con un conjunto de pruebas de carga destinado a validar las contramedidas implementadas. También fue la oportunidad de presentar la biblioteca de código abierto AWSSSMChaosRunner. La demostración se basa en una publicación de 2019 de Adrian Hornsby, desarrollador principal de AWS, y viene con un ejemplo de cómo Prime Video usa la biblioteca para evitar problemas que pueden afectar a los clientes. .
Agotamiento de recursos, un caso típico de experimentación
En la publicación del 18 de agosto, el ingeniero de software Varun Jewalikar y Adrian Hornsby recuerdan que las pruebas de software que se realizan comúnmente no tienen en cuenta todas las posibilidades de interrupción que pueden ocurrir en los sistemas distribuidos. En particular, aquellos que pueden estar relacionados con una interrupción en la zona de disponibilidad, una dependencia o un problema relacionado con la red, etc. “Generalmente, el comportamiento del software en estos escenarios sigue siendo desconocido”, explican los Sres. Jewalikar y Hornsby. “Por ejemplo, ¿qué pasa si una instancia Amazon EC2 en la flota del servicio admite un alto consumo de CPU? Tal situación puede ocurrir debido a un aumento inesperado en el tráfico o un bucle implementado incorrectamente en el código. " Es difícil tener total confianza en sistemas que no han sido probados.
¿Cuáles son los temas a considerar? AWS cita varios. Por ejemplo, ¿hemos probado cómo reacciona el sistema cuando las instancias subyacentes experimentan un aumento en el uso de la CPU? ¿Es suficiente el seguimiento de los sistemas? ¿Se han validado las alarmas? ¿Se han implementado contramedidas? “Por ejemplo, ¿el ajuste de escala automático está implementado y se comporta como se esperaba? ¿Son apropiados los tiempos de espera y los reintentos? ”, Lista de ingenieros de software de AWS. Entre los experimentos típicos de ingeniería del caos, citan el agotamiento de los recursos, que puede controlarse asegurando que las prácticas de monitoreo sean capaces de detectar fallas. Otro ejemplo es el de las dependencias de red fallidas o demasiado lentas. En el resto de la publicación, demuestran cómo usar la biblioteca AWSSSMChaosRunner para la inyección de fallas usando el software SSM Agent de código abierto que se instalará en una instancia EC2 para administrar y configurar recursos, la API SendCommand y los documentos asociados. Administrador de sistemas de AWS. La API de envío de comandos, por otro lado, le permite ejecutar comandos mediante programación en una o más instancias a través del Agente SSM.
Si quieres conocer otros artículos parecidos a AWS pone su servicio Prime Video a prueba de la ingeniería del caos puedes visitar la categoría Otros.
Otras noticias que te pueden interesar