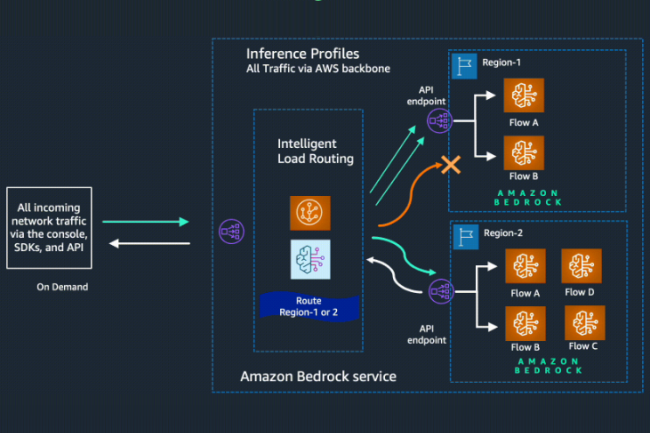
Ahora disponible para todos, la llamada función de referencia cruzada dentro del servicio generativo generativoAWS Transporta dinámicamente el tráfico a través de varias regiones. Por lo tanto, conserva una disponibilidad óptima para cada solicitud de aplicaciones alimentadas por Bedrock y para mejorar el rendimiento durante los períodos de alto uso.
Un modelo a pedido o por lotes
En el modo de demanda, los desarrolladores pagan por lo que usan sin compromiso a largo plazo, a diferencia del modo LOTS, para el cual proporcionan un conjunto de indicaciones en forma de un solo archivo de entrada y reciben respuestas en forma de un solo archivo de salida, lo que les permite obtener predicciones a gran escala simultáneas. "Al optar por este modo, los desarrolladores ya no tienen que prever las fluctuaciones de la demanda", escribió la compañía en una publicación de blog. "Además, esta característica da prioridad a la región primaria de origen/conectada de la API de lástima cuando sea posible, lo que reduce la latencia al mínimo y aumenta la reactividad. En consecuencia, los clientes pueden mejorar la confiabilidad, el rendimiento y la eficiencia de sus aplicaciones", agregó el proveedor.
Los desarrolladores pueden comenzar a usar inferencia interregional a través de API o la consola Bedrock AWS para definir la región primaria y todas las regiones secundarias donde las solicitudes se enrutarán en caso de picos de tráfico. Cuando se inicia la funcionalidad, los programadores podrán seleccionar un modelo basado en los Estados Unidos o un modelo de la Unión Europea, cada una de las cuales incluye dos o tres regiones predefinidas de estas ubicaciones geográficas. Actualmente, los modelos disponibles para la inferencia interregional incluyen el soneto Claude 3.5, la familia Claude 3 de grandes modelos de lenguaje (LLM), a saber, haiku, soneto y opus.
Cateling la latencia
AWS indicó que la funcionalidad intentará satisfacer cualquier solicitud de la región primaria primero antes de mudarse a una región secundaria, lo que conducirá a una latencia adicional durante el rebobinado. "Durante nuestras pruebas, notamos una latencia adicional a dos unidades en milisegundos", escribió el proveedor. Para obtener más claridad, los desarrolladores y empresas deben pagar el mismo precio por token para modelos individuales enumerados en comparación con su región principal o fuente para la inferencia interregional. Para esta característica, AWS dijo que no cobraría a los usuarios profesionales con transferencia de datos, cifrado, uso de la red y posibles diferencias de precios por millón de tokens por modelo.
Además, el proveedor de servicios en la nube explicó que las empresas deberían prestar especial atención a sus requisitos de residencia de datos y protección de la privacidad. "Incluso si no se almacenan datos del cliente en las regiones primarias o secundarias cuando se usan inferencia interregional, es importante tener en cuenta que los datos de inferencia se procesarán y transmitirán más allá de la región primaria", dijo la compañía. Además de AWS, Snowflake parece ser el único otro proveedor de servicios de LLM que ha introducido una inferencia interregional. A principios de mes, Snowflake entregó la funcionalidad como parte de sus funciones de IA y ML.
Por otro lado, los proveedores de servicios en la nube competitivos, como Google Cloud y Microsoft, ofrecen características similares en sus bases de datos, infraestructura y servicios de aprendizaje automático más antiguos. Si bien Google Cloud ofrece características similares en sus otros servicios, como Cloud Run y BigQuery, Microsoft ofrece puntos de terminación de inferencia como una opción libre de servidor a través de su servicio de aprendizaje automático Azure. Con respecto a BigQuery, Google Cloud permite la replicación interregional de conjuntos de datos. Del mismo modo, Azure ofrece a las empresas la posibilidad de responder datos entre las regiones en la nube.
Otras noticias que te pueden interesar