Rumbo a Ferret para Apple. Mientras la lista de proveedores que trabajan duro en su gran modelo lingüístico sigue creciendo (Claude de Anthropic, Llama de Meta, GPT de OpenAI, PaLM de Google, Mistral AI de Mistral...), hasta ahora un actor clave en la industria ha Apple ha sido bastante discreto al respecto. Si bien la empresa indicó que estaba interesada en el tema, hasta ahora no había presentado mucho concreto, pero ya lo ha hecho. El pasado mes de octubre, la firma Apple discretamente publicado en GitHub su trabajo en torno a su LLM, llamado Ferret, que desarrolla junto a la Universidad de Cornell (Nueva York).
“Los datos y el código están destinados únicamente a uso en investigación y están sujetos a licencia. También están limitados a usos consistentes con el acuerdo de licencia de LLaMA, Vicuña y GPT-4”, se lee en las notas de investigación. "El conjunto de datos es CC BY NC 4.0 (permite únicamente el uso no comercial) y los modelos entrenados con el conjunto de datos no deben usarse fuera del alcance de la investigación". Se entrenan dos modelos, concretamente con 7 y 13 mil millones de hiperparámetros. “Ferret fue entrenado en 8 GPU A100 con 80 GB de memoria. Para entrenar menos GPU, puede reducir el tamaño del lote de entrenamiento por dispositivo y aumentar la cantidad de pasos de acumulación de gradiente en consecuencia. El tamaño total del lote siempre debe ser el mismo: per_device_train_batch_size x gradient_accumulation_steps x num_gpus”, explica la descripción del proyecto.
Análisis contextual de imágenes a gran escala.
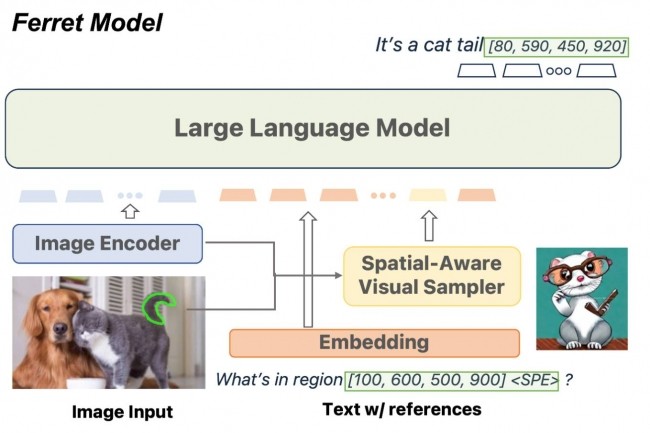
"Ferret te permite hacer referencia a una región de imagen de cualquier forma". explicado Zhe Gan, investigador del equipo de IA de Apple. "A menudo muestra una comprensión más precisa de pequeñas regiones de la imagen que GPT-4V". Este LLM examina una región específica de una imagen, determina qué elementos podrían ser útiles en respuesta a una consulta, identifica estos elementos y dibuja un cuadro alrededor de ellos. Luego puede utilizar los elementos identificados a raíz de una solicitud de un usuario, por ejemplo, si el usuario resalta la imagen de un animal en una imagen más grande y luego le pregunta al LLM qué animal es, responderá a esta consulta identificando la esperanza en pregunta. Luego puede utilizar el contexto de otros elementos detectados en la imagen para proporcionar otras respuestas, por ejemplo, qué está haciendo un animal.
Otras noticias que te pueden interesar